- De
- En

Sprach- und text-basierte Forschungsdaten sind in vielen geistes- und kulturwissenschaftlichen Disziplinen von herausragender Bedeutung. Zunächst mit den Datendomänen Sammlungen, lexikalische Ressourcen und Editionen adressiert Text+ die Anforderungen einer breiten Palette von Forschungsfeldern, die sich auf eine lange Forschungstradition stützen. Diese Datendomänen sind mit ausgereiften methodologischen Paradigmen verknüpft, die charakteristische, aber auch bereichsübergreifende Praktiken der Erzeugung, Kuratierung und des Managements von Daten erfordern.
Dabei beschränkt sich Text+ nicht nur auf Bestandsdaten, sondern wird sein Angebotsportfolio in enger Absprache mit den beteiligten Fachcommunities systematisch erweitern. Dazu gehören auch Werkzeuge, um Forschende im gesamten Forschungsdatenlebenszyklus bei der FAIRen Erstellung, Nutzung und Bereitstellung von Daten zu unterstützen.
Die Nutzungsfreundlichkeit der Daten und Werkzeuge verbunden mit der rechtskonformen Nutzung von Sprach- und Textdaten, die häufig Rechte Dritter berührt, sind zentrale Aufgaben von Text+. Hinzu kommt die Diversität der Daten, die bezüglich Sprachräumen (auch über Europa hinaus) und Modalitäten von Sprache und Schriftsystemen heterogen sind; das +-Zeichen weist darauf hin, dass Text+ offen ist, z. B. auch für sprachbasierte Ressourcen und Werkzeuge für gesprochene Sprache und für multimodale Daten. Als ortsverteilte Infrastruktur kann Text+ auf vielfältige Bestandsdaten und Werkzeuge der derzeit mehr als 30 Verbundpartner zurückgreifen.
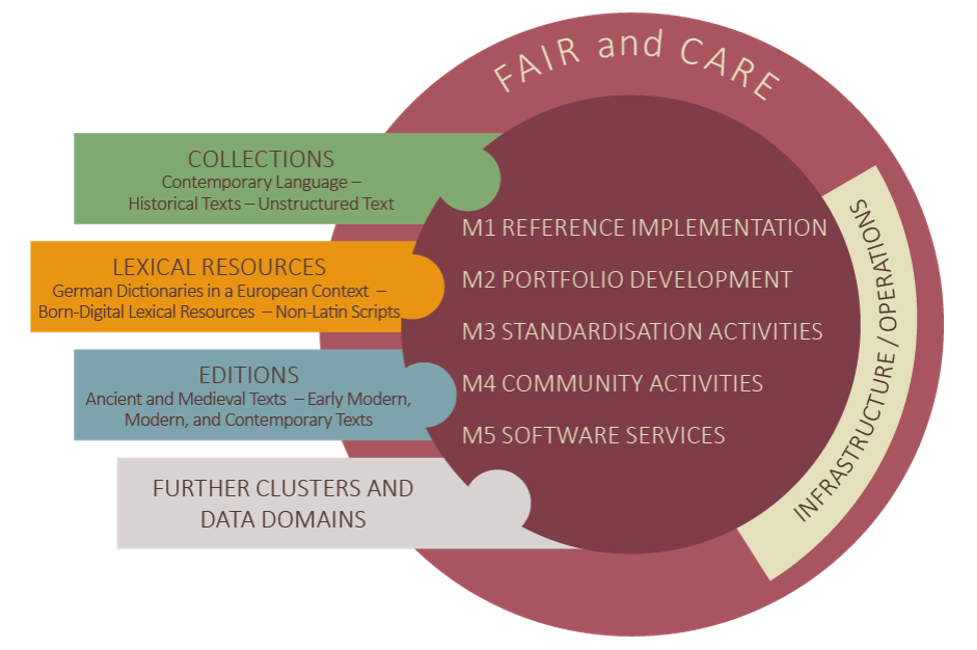
Die GWDG ist im Bereich Network Infrastructure/Operations beteiligt. Die GWDG bringt Kompetenzen im Bereich Authentication Authorization Infrastructure (AAI) und Persistant Identifiers (PID) in Text+ ein und baut diese weiter aus.
Das Konsortium setzt sich aus zahlreichen Organisationen zusammen. Eine vollständige Übersicht finden Sie auf der Webseite der NFDI Text+.
01.10.2021 - 30.09.2026
![]() Project grant: 460033370
Project grant: 460033370

